The Data Warehouse Schema is a structure that rationally defines the contents of the Data Warehouse, by facilitating the operations performed on the Data Warehouse and the maintenance activities of the Data Warehouse system, which usually includes a detailed description of the databases, tables, views, indexes, and the Data, that are regularly structured using predefined design types such as Star Schema, Snowflake Schema, Galaxy Schema (also known as Fact Constellation Schema).
What is Data Warehouse?
The Data Warehouse (DW) or the Enterprise Data Warehouse (EDW) is the essential component for Business Intelligence (BI) systems, in which the process of assembling, administering, and manipulating the data from multiple varieties of data sources is performed in order to turn up with the significant business decision-making measures, by using the EDW as a way to associate and analyze the data related to the business requirements for which the Business Intelligence is necessitated in the form of Reporting and Analysis.
Data warehouses are considered one of the most critical components of business intelligence. They serve as central repositories of integrated data obtained from multiple sources, storing current and historical data in one place. This data is used to create analytical reports for all workers throughout the enterprise. Typically, data is uploaded to the warehouse from operational systems, such as marketing or sales, passing through an operational data store and undergoing data cleansing to ensure the data’s quality before being used in the EDW for reporting. Then comes the activity of ETL (Extract, Transform, Load), which makes use of staging, data integration, and access layers to make use of key functions.
In simple terms, a data warehouse is a system used to report and store data. The data is first generated in various systems such as RDBMS, Oracle, and Mainframes, then transferred to the data warehouse for long-term storage to be used for analytical purposes. This storage is structured to allow users from different divisions or departments within an organization to access and analyze the data according to their individual needs and requirements.
These are analytical tools that are solely built to provide support in the decision-making process and a system for reporting to users for many departments. They are also archival data, consisting of historical usage data of the organization, which is specifically not maintained in operational systems. In essence, they are used to create a single version of truth for the entire organization. It maintains the copy of information and data from source transaction systems.
- Integrates data from multiple sources and puts it into one database or a model; therefore, a single query engine.
can be used to put data in ODS (operational data store). - Helps in mitigation of database isolation level lock problem, which was generally caused due by large, long-running, analytical queries.
- Data history is maintained even if the source transactional systems are not maintaining it.
- A central view across the enterprise can be seen once all the data is put from multiple resources.
- Code consistency and descriptions and even fixing bad data are improved. Basically impacts the overall data quality.
A schema is a logical description that describes the entire database. In the data warehouse there includes the name and description of records. It has all data items and also different aggregates associated with the data. Like a database has a schema, it is required to maintain a schema for a data warehouse as well. There are different schemas based on the setup and data which are maintained in a data warehouse. Following are the three major types of schemas:
- Star Schema
- Snowflake Schema
- Galaxy Schema
There are fact tables and dimension tables that form the basis of any schema in the data warehouse that are important to be understood. The fact tables should have data corresponding data to any business process. Every row represents any event that can be associated with any process. It stores quantitative information for analysis. A dimension table stores data about how the data in the fact table is being analyzed. They facilitate the fact table in gathering different dimensions of the measures which are to be taken.
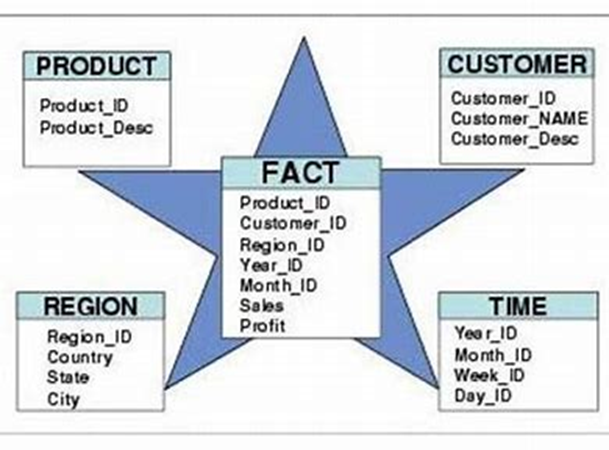
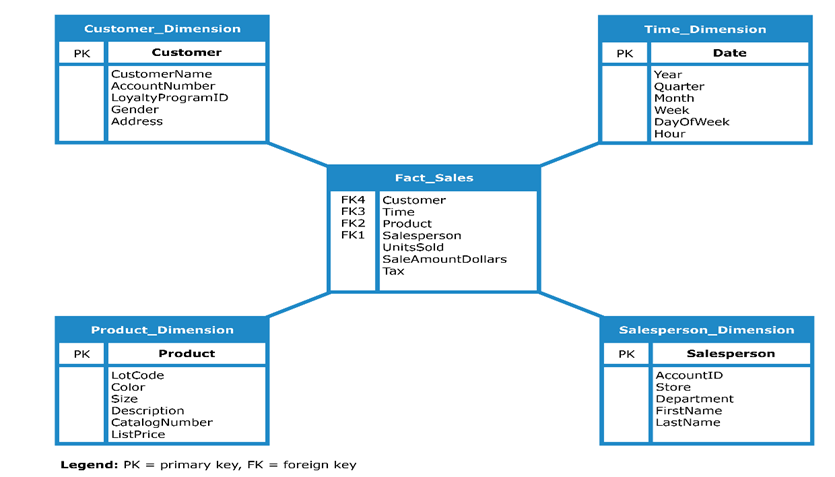
Star Schema
Here are some of the basic points of star schema which are as follows:
- In a star schema, as the structure of a star, there is one fact table in the middle and a number of associated dimension tables. This structure resembles a star and hence it is known as a star schema.
- The fact table here consists of primary information in the data warehouse. It surrounds the smaller dimension lookup tables which will have details for different fact tables. The primary key which is present in each dimension is related to a foreign key which is present in the fact table.
- This infers that a fact table has two types of columns having foreign keys to dimension tables and measures that contain numeric facts. At the center of the star, there is a fact table and the points of the star are the dimension tables.
- The fact tables are in 3NF form and the dimension tables are in denormalized form. Every dimension in the star schema should be represented by only a one-dimensional table. The dimension table should be joined to a fact table. The fact table should have a key and measure.
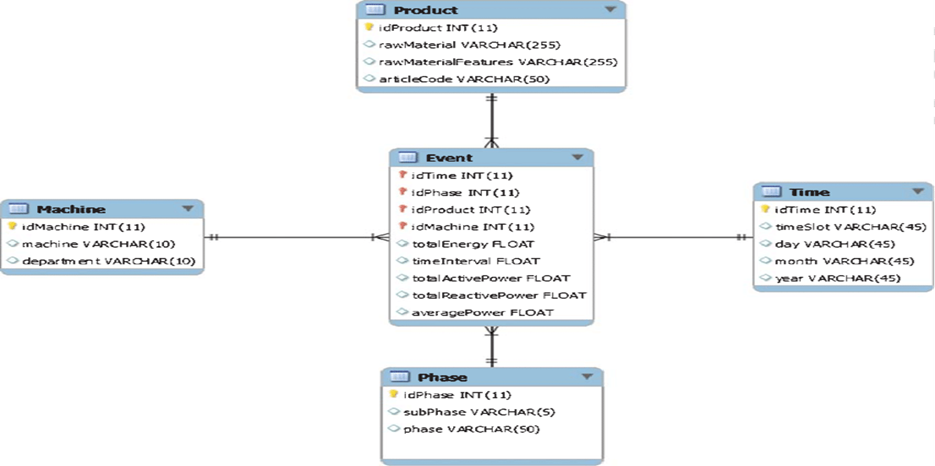
Snowflake Schema
Here are some of the basic points of the snowflake schema which are as follows:
- Snowflake schema acts like an extended version of a star schema. There are additional dimensions added to the Star schema. This schema is known as snowflake due to its structure.
- In this schema, the centralized fact table will be connected to different multiple dimensions. The dimensions present are in normalized form from the multiple related tables which are present. The snowflake structure is detailed and structured when compared to the star schema.
- There are multiple levels of relationships and child tables involved that have multiple parent tables. In the snowflake schema, the affected tables are only the dimension tables and not the fact tables.
- The difference between star and snowflake schema is that the dimensions of snowflake schema are maintained in such a way that they reduce the redundancy of data. The tables are easy to manage and maintain. They also save storage space.
- However, due to this, it is needed to have more joins in the query in order to execute the query. The further expansion of the tables leads to snowflaking. When a dimension table has a low cardinality attribute of dimensions then it is said to be snowflaked.
- The dimension tables have been divided into segregated normalized tables. Once they are segregated they are further joined with the original dimension table which has a referential constraint. This schema may hamper the performance as the number of tables that are required are more so that the joins are satisfied.
- The advantage of snowflake schema is that it uses small disk space. The implementation of dimensions is easy when they are added to this schema. The same set of attributes is published by different sources.


Fact Constellation Schema or Galaxy Schema
Here are some of the basic points of fact constellation schema which are as follows:
- A fact constellation can consist of multiple fact tables. These are more than two tables that share the same dimension tables. This schema is also known as galaxy schema.
- It is viewed as a collection of stars and hence the name galaxy. The shared dimensions in this schema are known as conformed dimensions. The dimensions in this schema are separated into segregated dimensions which are having different levels of hierarchy.
- As an example, we can consider the four levels of hierarchy taking geography into consideration as region, country, state, and city. This galaxy schema has four dimensions. Another way of creating a galaxy schema is by splitting a one-star schema into more star schemas.
- The dimensions are created as large and built on the basis of hierarchy. This schema is useful when aggregation of fact tables is necessary. Fact constellations are considered to be more complex than star and snowflake schemas. These are considered to be more flexible but hard to implement and maintain.
- This type of schema is usually used for sophisticated applications. The multiple numbers of tables present in this schema make it difficult and complex. Implementing this schema is hence difficult. The architecture is thus more complex when compared to the star and snowflake schema.

