In many large-scale solutions, data is divided into partitions that can be managed and accessed separately. Partitioning can improve scalability, reduce contention, and optimize performance. It can also provide a mechanism for dividing data by usage pattern. For example, you can archive older data in cheaper data storage. However, the partitioning strategy must be chosen carefully to maximize the benefits while minimizing adverse effects.
Why partition data?
Improve scalability. When you scale up a single database system, it will eventually reach a physical hardware limit. If you divide data across multiple partitions, each hosted on a separate server, you can scale out the system almost indefinitely.
Improve performance. Data access operations on each partition take place over a smaller volume of data. Correctly done, partitioning can make your system more efficient. Operations that affect more than one partition can run in parallel.
Improve security. In some cases, you can separate sensitive and nonsensitive data into different partitions and apply different security controls to the sensitive data.
Provide operational flexibility. Partitioning offers many opportunities for fine-tuning operations, maximizing administrative efficiency, and minimizing cost. For example, you can define different strategies for management, monitoring, backup and restore, and other administrative tasks based on the importance of the data in each partition.
Match the data store to the pattern of use. Partitioning allows each partition to be deployed on a different type of data store, based on cost and the built-in features that data store offers. For example, large binary data can be stored in blob storage, while more structured data can be held in a document database.
Improve availability. Separating data across multiple servers avoids a single point of failure. If one instance fails, only the data in that partition is unavailable. Operations on other partitions can continue. For managed platform as a service (PaaS) data stores, this consideration is less relevant, because these services are designed with built-in redundancy.
Designing partitions
There are three typical strategies for partitioning data:
Horizontal partitioning (often called sharding). In this strategy, each partition is a separate data store, but all partitions have the same schema. Each partition is known as a shard and holds a specific subset of the data, such as all the orders for a specific set of customers.
Vertical partitioning. In this strategy, each partition holds a subset of the fields for items in the data store. The fields are divided according to their pattern of use. For example, frequently accessed fields might be placed in one vertical partition and less frequently accessed fields in another.
Functional partitioning. In this strategy, data is aggregated according to how it is used by each bounded context in the system. For example, an e-commerce system might store invoice data in one partition and product inventory data in another.
These strategies can be combined, and it is recommended to consider them all when you design a partitioning scheme. For example, you might divide data into shards and then use vertical partitioning to further subdivide the data in each shard.
Horizontal partitioning (sharding)
Figure 1 shows horizontal partitioning or sharding. In this example, product inventory data is divided into shards based on the product key. Each shard holds the data for a contiguous range of shard keys (A-G and H-Z), organized alphabetically. Sharding spreads the load over more computers, which reduces contention and improves performance.
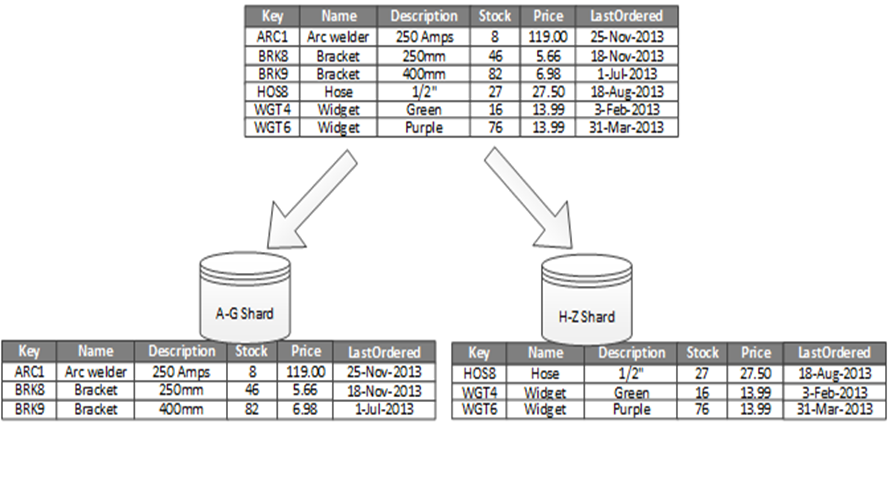
The most important factor is the choice of a sharding key. It can be difficult to change the key after the system is in operation. The key must ensure that data is partitioned to spread the workload as evenly as possible across the shards.
The shards don’t have to be the same size. It’s more important to balance the number of requests. Some shards might be very large, but each item has a low number of access operations. Other shards might be smaller, but each item is accessed much more frequently. It’s also important to ensure that a single shard does not exceed the scale limits (in terms of capacity and processing resources) of the data store.
Avoid creating “hot” partitions that can affect performance and availability. For example, using the first letter of a customer’s name causes an unbalanced distribution, because some letters are more common. Instead, use a hash of a customer identifier to distribute data more evenly across partitions.
Choose a sharding key that minimizes any future requirements to split large shards. These operations can be very time-consuming and might require taking one or more shards offline while they are performed.
If shards are replicated, it might be possible to keep some of the replicas online while others are split, merged, or reconfigured. However, the system might need to limit the operations that can be performed during the reconfiguration. For example, the data in the replicas might be marked as read-only to prevent data inconsistencies.
Vertical partitioning
The most common use for vertical partitioning is to reduce the I/O and performance costs associated with fetching items that are frequently accessed. Figure 2 shows an example of vertical partitioning. In this example, different properties of an item are stored in different partitions. One partition holds data that is accessed more frequently, including product name, description, and price. Another partition holds inventory data: the stock count and last-ordered date.
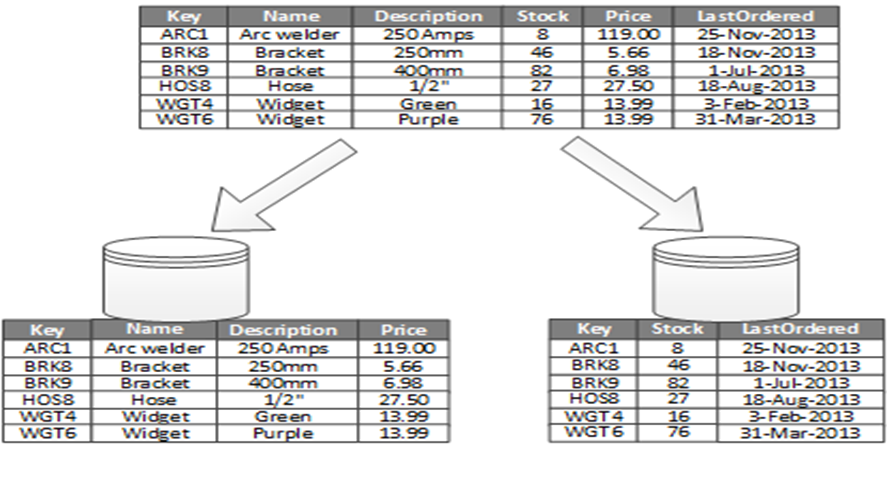
In this example, the application regularly queries the product name, description, and price when displaying the product details to customers. Stock count and last- ordered date are held in a separate partition because these two items are commonly used together.
Other advantages of vertical partitioning:
- Relatively slow-moving data (product name, description, and price) can be separated from the more dynamic data (stock level and last ordered date). Slow moving data is a good candidate for an application to cache in memory.
- Sensitive data can be stored in a separate partition with additional security controls.
- Vertical partitioning can reduce the amount of concurrent access that’s needed.
Vertical partitioning operates at the entity level within a data store, partially normalizing an entity to break it down from a wide item to a set of narrow items. It is ideally suited for column-oriented data stores such as HBase and Cassandra. If the data in a collection of columns is unlikely to change, you can also consider using column stores in SQL Server.
What is HBase? -Apache HBase is an open-source, NoSQL, distributed database for big data stores. This NoSQL database enables random, strictly consistent, real-time access to massive amounts of data (petabytes). HBase is column-oriented which means data is stored in individual columns that are indexed by unique row keys. Data and queries are distributed across the cluster of servers, which makes for very fast retrieval of results (often in the order of milliseconds). This allows for the rapid retrieval of both rows and columns to help make it a viable option for very large database stores. HBase is used to store non-relational data, which is accessed via the HBase API.
What is Cassandra? – Apache Cassandra is another open-source, NoSQL, distributed database used for massive stores of data. Unlike some NoSQL distributed databases, Cassandra is a “masterless” architecture (so all nodes provide the same functionality within the cluster) that can withstand a data center outage with zero data loss, even across public or private clouds. Cassandra is prized for its scalability, high-availability, and performance. Apache Cassandra can be deployed on either commodity hardware or a cloud infrastructure making it an ideal option for mission-critical data. Cassandra is one of the most performant NoSQL databases on the market, so if your project or business needs a database geared toward speed, this might be the perfect option.
Functional partitioning
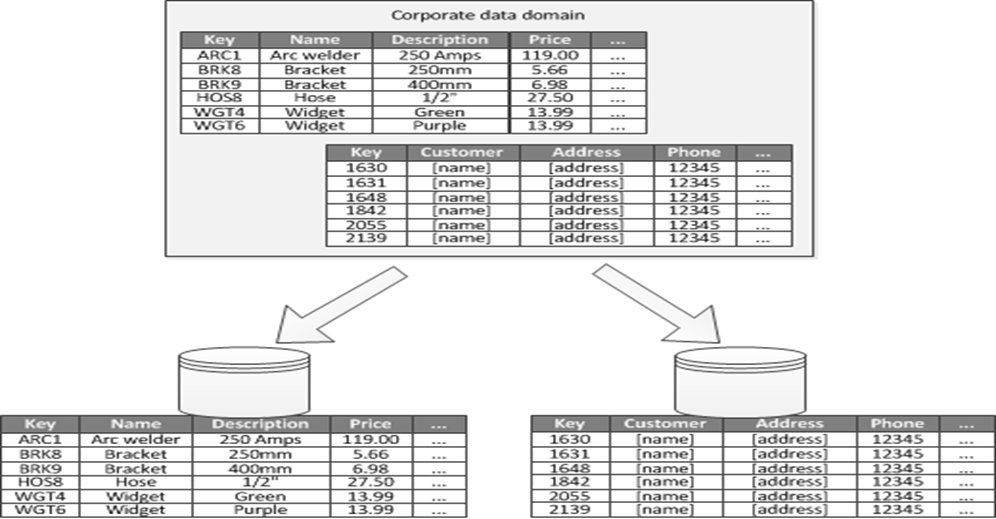
When it’s possible to identify a bounded context for each distinct business area in an application, functional partitioning is a way to improve isolation and data access performance. Another common use for functional partitioning is to separate read-write data from read-only data. Figure 3 shows an overview of functional partitioning where inventory data is separated from customer data.
This partitioning strategy can help reduce data access contention across different parts of a system.
CQRS pattern – CQRS stands for Command and Query Responsibility Segregation, a pattern that separates read and update operations for a data store. Implementing CQRS in your application can maximize its performance, scalability, and security. The flexibility created by migrating to CQRS allows a system to better evolve over time and prevents update commands from causing merge conflicts at the domain level.
Context and problem – In traditional architectures, the same data model is used to query and update a database. That’s simple and works well for basic CRUD operations. In more complex applications, however, this approach can become unwieldy. For example, on the read side, the application may perform many different queries, returning data transfer objects (DTOs) with different shapes. Object mapping can become complicated. On the write side, the model may implement complex validation and business logic. As a result, you can end up with an overly complex model that does too much. Read and write workloads are often asymmetrical, with very different performance and scale requirements.
- There is often a mismatch between the read and write representations of the data, such as additional columns or properties that must be updated correctly even though they aren’t required as part of an operation.
- Data contention can occur when operations are performed in parallel on the same set of data.
- The traditional approach can have a negative effect on performance due to load on the data store and data access layer, and the complexity of queries required to retrieve information.
- Managing security and permissions can become complex, because each entity is subject to both read and write operations, which might expose data in the wrong context.
Solution – CQRS separates reads and writes into different models, using commands to update data, and queries to read data.
- Commands should be task-based, rather than data centric. This may require some corresponding changes to the user interaction style. The other part of that is to look at modifying the business logic processing those commands to be successful more frequently. One technique that supports this is to run some validation rules on the client even before sending the command. In that manner, the cause for server-side command failures can be narrowed to race conditions (two users trying to book the last room), and even those can sometimes be addressed with some more data and logic (putting a guest on a waiting list).
- Commands may be placed on a queue for asynchronous processing, rather than being processed synchronously.
- Queries never modify the database. A query returns a DTO that does not encapsulate any domain knowledge.
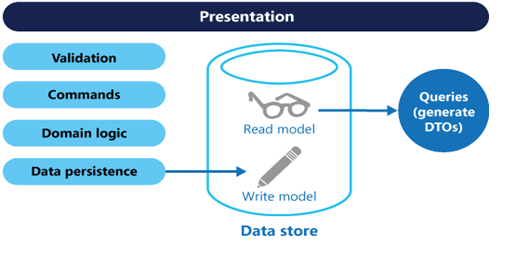
Having separate query and update models simplifies the design and implementation. For greater isolation, you can physically separate the read data from the write data. In that case, the read database can use its own data schema that is optimized for queries.

The read store can be a read-only replica of the write store, or the read and write stores can have a different structure altogether. Using multiple read-only replicas can increase query performance, especially in distributed scenarios where read-only replicas are located close to the application instances. Separation of the read and write stores also allows each to be scaled appropriately to match the load. For example, read stores typically encounter a much higher load than write stores.
Designing partitions for scalability
It’s vital to consider size and workload for each partition and balance them so that data is distributed to achieve maximum scalability. However, you must also partition the data so that it does not exceed the scaling limits of a single partition store.
The following are the steps to be considered when designing partitions for scalability:
- Analyze the application to understand the data access patterns, such as the size of the result set returned by each query, the frequency of access, the inherent latency, and the server-side compute processing requirements. In many cases, a few major entities will demand most of the processing resources.
Use this analysis to determine the current and future scalability targets, such as data size and workload. Then distribute the data across the partitions to meet the scalability target.
- For horizontal partitioning, choosing the right shard key is important to make sure distribution is even.
- Make sure each partition has enough resources to handle the scalability requirements, in terms of data size and throughput. Depending on the data store, there might be a limit on the amount of storage space, processing power, or network bandwidth per partition. If the requirements are likely to exceed these limits, you might need to refine your partitioning strategy or split data out further, possibly combining two or more strategies.
- Monitor the system to verify that data is distributed as expected and that the partitions can handle the load. Actual usage does not always match what an analysis predicts. If so, it might be possible to rebalance the partitions, or else redesign some parts of the system to gain the required balance.
Designing partitions for query performance
Query performance can often be boosted by using smaller data sets and by running parallel queries. Each partition should contain a small proportion of the entire data set. This reduction in volume can improve the performance of queries. However, partitioning is not an alternative for designing and configuring a database appropriately. For example, make sure that you have the necessary indexes in place.
The following are the steps to be considered when designing partitions for query performance:
- Examine the application requirements and performance:
- Use business requirements to determine the critical queries that must always perform quickly.
- Monitor the system to identify any queries that perform slowly.
- Find which queries are performed most frequently. Even if a single query has a minimal cost, the cumulative resource consumption could be significant.
- Partition the data that is causing slow performance:
- Limit the size of each partition so that the query response time is within target.
- If you use horizontal partitioning, design the shard key so that the application can easily select the right partition. This prevents the query from having to scan through every partition.
- Consider the location of a partition. If possible, try to keep data in partitions that are geographically close to the applications and users that access it.
- If an entity has throughput and query performance requirements, use functional partitioning based on that entity. If this still doesn’t satisfy the requirements, apply horizontal partitioning as well. In most cases, a single partitioning strategy will suffice, but in some cases it is more efficient to combine both strategies.
- Consider running queries in parallel across partitions to improve performance.
Designing partitions for availability
Partitioning data can improve the availability of applications by ensuring that the entire dataset does not constitute a single point of failure and that individual subsets of the dataset can be managed independently.
Consider the following factors that affect availability:
How critical the data is to business operations. Identify which data is critical business information, such as transactions, and which data is less critical operational data, such as log files.
- Consider storing critical data in highly available partitions with an appropriate backup plan.
- Establish separate management and monitoring procedures for the different datasets.
- Place data that has the same level of criticality in the same partition so that it can be backed up together at an appropriate frequency. For example, partitions that hold transaction data might need to be backed up more frequently than partitions that hold logging or trace information.
Designing partitions to support independent management and maintenance provides several advantages. For example:
- If a partition fails, it can be recovered independently without applications that access data in other partitions.
- Partitioning data by geographical area allows scheduled maintenance tasks to occur at off-peak hours for each location. Ensure that partitions are not too large to prevent any planned maintenance from being completed during this period.
Application design considerations
Partitioning adds complexity to the design and development of your system. Consider partitioning as a fundamental part of system design even if the system initially only contains a single partition. If you address partitioning as an afterthought, it will be more challenging because you already have a live system to maintain:
- Data access logic will need to be modified.
- Large quantities of existing data might need to be migrated, to distribute it across partitions.
- Users expect to be able to continue using the system during the migration.
In some cases, partitioning is not considered important because the initial dataset is small and can be easily handled by a single server. This might be true for some workloads, but many commercial systems need to expand as the number of users increases.
Moreover, it’s not only large data stores that benefit from partitioning. For example, a small data store might be heavily accessed by hundreds of concurrent clients. Partitioning the data in this situation can help to reduce contention and improve throughput.
Consider the following points when you design a data partitioning scheme:
- Minimize cross-partition data access operations. Where possible, keep data for the most common database operations together in each partition to minimize cross-partition data access operations.
Consider replicating static reference data. If queries use relatively static reference data, such as postal code tables or product lists, consider replicating this data in all of the partitions to reduce separate lookup operations in different partitions. This approach can also reduce the likelihood of the reference data becoming a “hot” dataset, with heavy traffic from across the entire system. However, there is an additional cost associated with synchronizing any changes to the reference data.
- Minimize cross-partition joins. Where possible, minimize requirements for referential integrity across vertical and functional partitions. In these schemes, the application is responsible for maintaining referential integrity across partitions. Queries that join data across multiple partitions are inefficient because the application typically needs to perform consecutive queries based on a key and then a foreign key. Instead, consider replicating or de-normalizing the relevant data. If cross-partition joins are necessary, run parallel queries over the partitions and join the data within the application.
- Embrace eventual consistency. Evaluate whether strong consistency is actually a requirement. A common approach in distributed systems is to implement eventual consistency. The data in each partition is updated separately, and the application logic ensures that the updates are all completed successfully. It also handles the inconsistencies that can arise from querying data while an eventually consistent operation is running.
- Consider how queries locate the correct partition. If a query must scan all partitions to locate the required data, there is a significant impact on performance, even when multiple parallel queries are running. With vertical and functional partitioning, queries can naturally specify the partition. Horizontal partitioning, on the other hand, can make locating an item difficult, because every shard has the same schema. A typical solution to maintain a map that is used to look up the shard location for specific items. This map can be implemented in the sharding logic of the application, or maintained by the data store if it supports transparent sharding.
- Consider periodically rebalancing shards. With horizontal partitioning, rebalancing shards can help distribute the data evenly by size and by workload to minimize hotspots, maximize query performance, and work around physical storage limitations. However, this is a complex task that often requires the use of a custom tool or process.
- Replicate partitions. If you replicate each partition, it provides additional protection against failure. If a single replica fails, queries can be directed toward a working copy.
- If you reach the physical limits of a partitioning strategy, you might need to extend the scalability to a different level. For example, if partitioning is at the database level, you might need to locate or replicate partitions in multiple databases. If partitioning is already at the database level, and physical limitations are an issue, it might mean that you need to locate or replicate partitions in multiple hosting accounts.
- Avoid transactions that access data in multiple partitions. Some data stores implement transactional consistency and integrity for operations that modify data, but only when the data is located in a single partition. If you need transactional support across multiple partitions, you will probably need to implement this as part of your application logic because most partitioning systems do not provide native support.
- All data stores require some operational management and monitoring activity. The tasks can range from loading data, backing up and restoring data, reorganizing data, and ensuring that the system is performing correctly and efficiently.
Consider the following factors that affect operational management:
- How to implement appropriate management and operational tasks when the data is partitioned. These tasks might include backup and restore, archiving data, monitoring the system, and other administrative tasks. For example, maintaining logical consistency during backup and restore operations can be a challenge.
- How to load the data into multiple partitions and add new data that’s arriving from other sources. Some tools and utilities might not support sharded data operations such as loading data into the correct partition.
- How to archive and delete the data on a regular basis. To prevent the excessive growth of partitions, you need to archive and delete data on a regular basis (such as monthly). It might be necessary to transform the data to match a different archive schema.
- How to locate data integrity issues. Consider running a periodic process to locate any data integrity issues, such as data in one partition that references missing information in another. The process can either attempt to fix these issues automatically or generate a report for manual review.
Rebalancing partitions
As a system matures, you might have to adjust the partitioning scheme. For example, individual partitions might start getting a disproportionate volume of traffic and become hot, leading to excessive contention. Or you might have underestimated the volume of data in some partitions, causing some partitions to approach capacity limits.
Some data stores, such as Azure Cosmos DB, can automatically rebalance partitions. In other cases, rebalancing is an administrative task that consists of two stages:
- Determine a new partitioning strategy.
- Which partitions need to be split (or possibly combined)?
- What is the new partition key?
- Migrate data from the old partitioning scheme to the new set of partitions.
Depending on the data store, you might be able to migrate data between partitions while they are in use. This is called online migration. If that’s not possible, you might need to make partitions unavailable while the data is relocated (offline migration).

Leave a comment